The article includes visualizations of how parameters from the AIView, AIHost, and per-provider LLM plugins combine at runtime. Where the exact ordering lives in the MedusaLLM / LLMRouter package (not in this repo) it is marked inferred; the gate inequalities and trigger formulas are taken verbatim from the AIHost appsettings annotations.
- Token-budget Pipeline (limits across stages)
- Model selection / routing (Auto vs Manual)
- Credential & Access-Gate Flow
- MCP tool availability (compounding gates)
- Circuit-breaker States (Llm:CircuitBreaker)
Token-budget Pipeline (limits across stages)
How one turn’s tokens flow through admission → sizing → compression → routing → generation, and which knob acts at each stage.

MaxTokensin the gate and the output cap is the same per-request output budget (Aife:Llm:MaxOutputTokens, or the router’s 4096 default when0).- Compression runs before routing, so it lowers
EstimatedInputTokensand can make a smaller-window model eligible.
Model selection / routing (Auto vs Manual)
How a model is chosen and how the ModelCapabilities fields filter candidates.

The filter criteria (window, complexity, modality, use-case) come from the documented
ModelCapabilitiesfields and theLlm:Routinggate; the precise rank ordering (cost vsPriority) is owned by the LLMRouter package and is marked inferred.Manualstill passes through generation; whether a manually pinned model bypasses the window gate is router-defined (not asserted here).
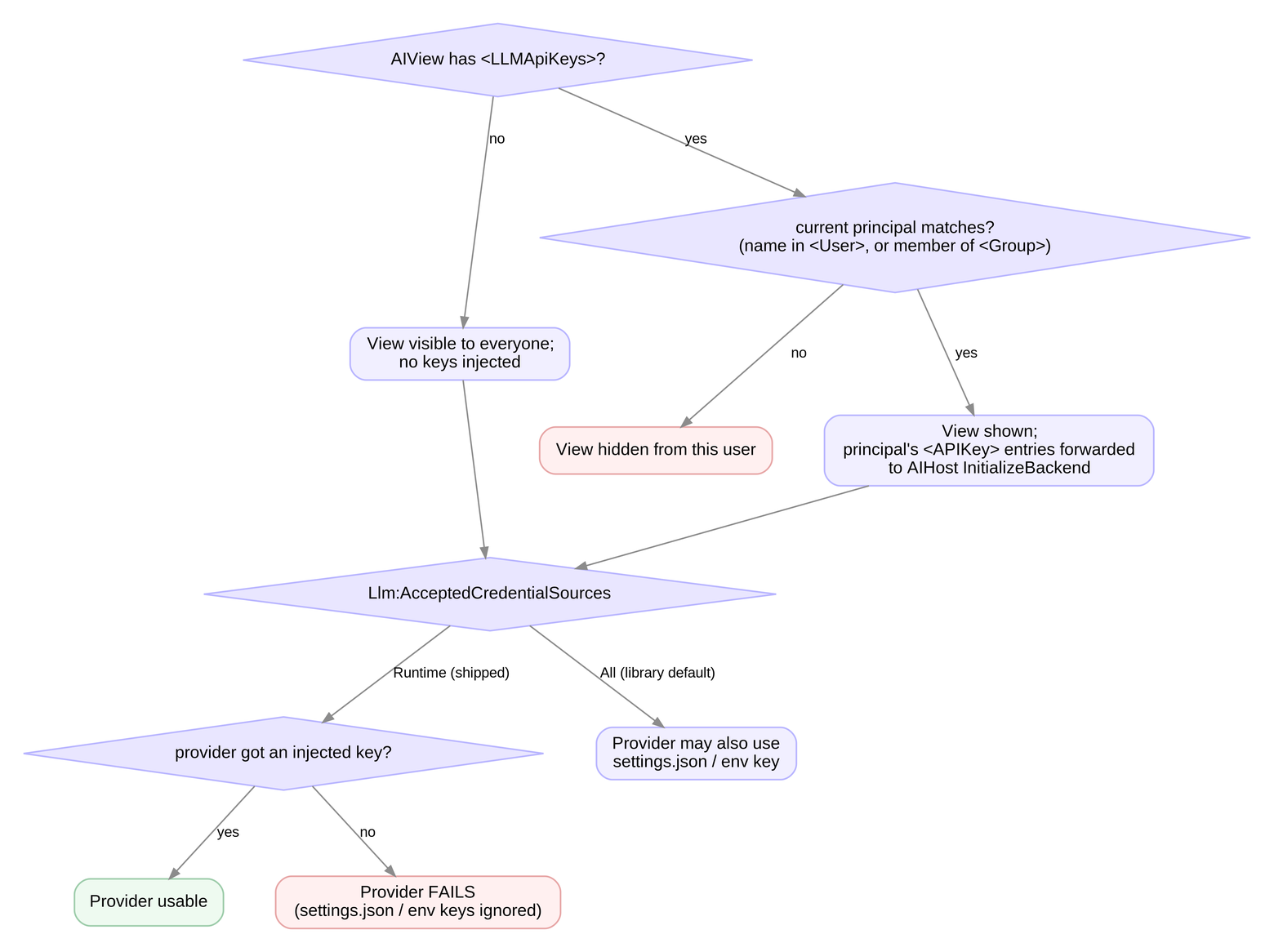
Credential & Access-Gate Flow
(<LLMApiKeys> ↔︎ AcceptedCredentialSources)
MCP tool availability (compounding gates)
“Will an MCP-discovered tool actually reach the model?”

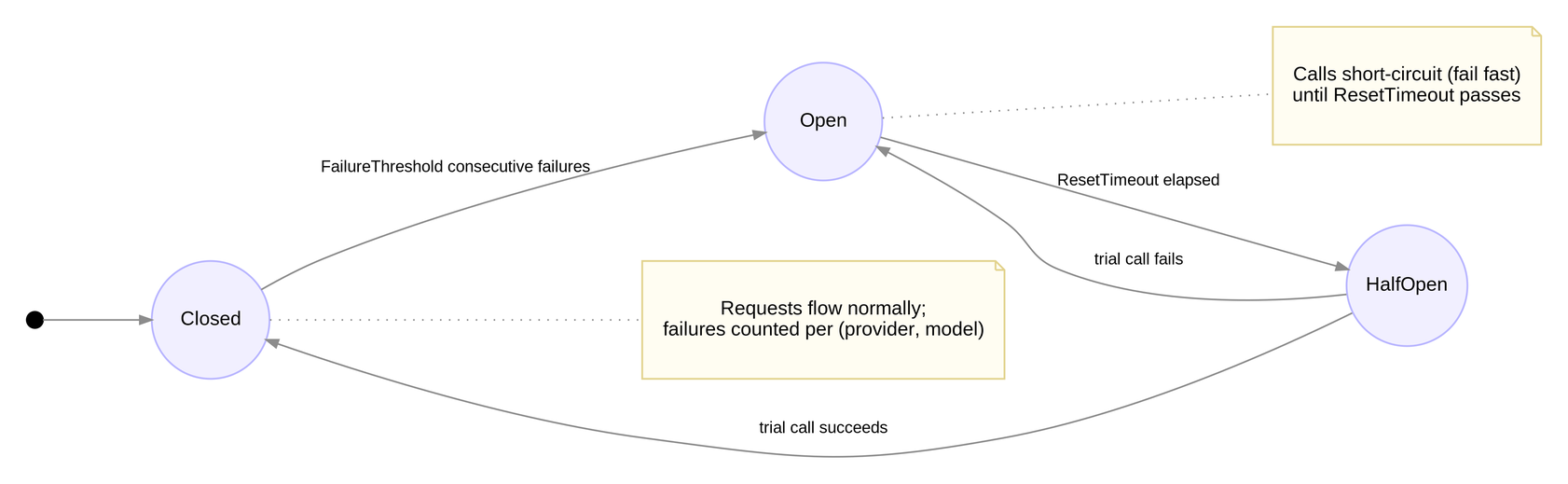
Circuit-breaker States (Llm:CircuitBreaker)
Process-local breaker keyed by (provider, model). When Enabled=false the breaker is bypassed entirely.